Секреты X-ray: 5 шагов для поиска утечек в PDF-документах (на Python)

Утечка данных: что такое «плохое замазывание» и чем оно опасно?
В работе с документами безопасность часто становится последним этапом, о котором вспоминают разработчики. Мы привыкли шифровать базы данных и настраивать HTTPS, но забываем о файлах, которые генерирует или отдает наша система. Одной из самых частых причин утечки конфиденциальной информации становится «плохое замазывание PDF» (bad redaction).
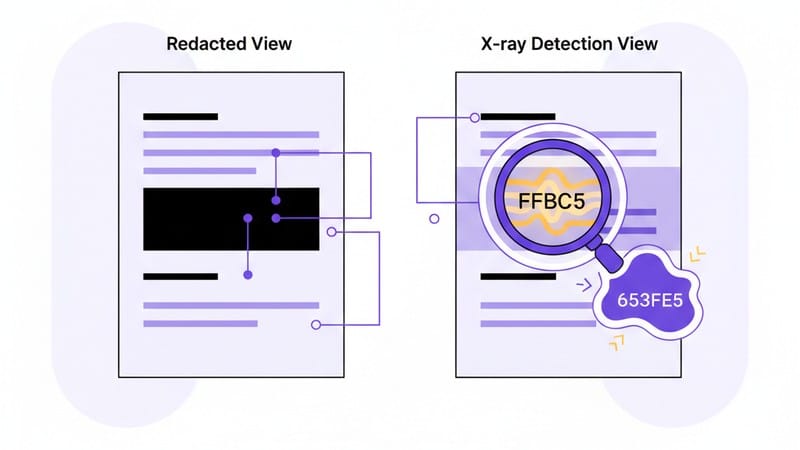
Проблема кроется в архитектуре самого формата PDF. Это не просто картинка, а слоеный пирог из векторов, растровой графики и текстовых слоев. Когда пользователь или некорректно настроенный скрипт пытается скрыть паспортные данные или сумму контракта, рисуя черный прямоугольник поверх текста, происходит визуальное перекрытие. Для глаза человека и при печати на принтере информация действительно скрыта.
Однако для компьютера текст под черным прямоугольником остается доступным. Достаточно открыть документ, выделить область «замазки» курсором и скопировать текст, либо воспользоваться программными методами извлечения данных. Это создает иллюзию безопасности, которая может стоить компании репутации и юридических исков.
Давайте разберёмся, как автоматизировать поиск таких уязвимостей и исключить человеческий фактор при проверке документов ↓
X-ray: как работает библиотека и быстрая установка
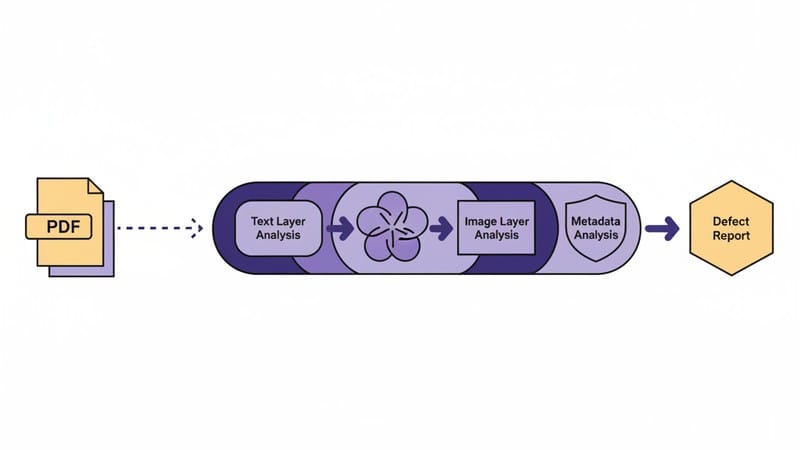
Для решения проблемы скрытых слоев команда Free Law Project разработала инструмент с говорящим названием X-ray. Это библиотека на Python, созданная специально для анализа структуры PDF-файлов и выявления пересечений между скрывающими элементами и текстовым слоем.
X-ray Python не занимается оптическим распознаванием символов (OCR) в привычном понимании. Вместо этого он анализирует внутренние объекты документа. Если утилита находит текст, который геометрически находится под непрозрачным объектом (например, черным прямоугольником), она помечает это как потенциальную утечку. Это делает проверку гораздо более точной, чем попытки визуального анализа.
Установка инструмента
Библиотеку можно использовать как CLI-утилиту или встраивать в свой Python-код. Рассмотрим варианты установки для разных окружений.
- Вариант 1: Использование через uv (рекомендуемый современный метод)
Если вы используете менеджер пакетов uv, установка происходит одной командой. Это обеспечивает высокую скорость разрешения зависимостей.
uv add x-ray
- Вариант 2: Классическая установка через pip
Для стандартных окружений Python (подходит для Windows, macOS и Linux) используйте привычный менеджер пакетов. Рекомендуется выполнять установку в виртуальном окружении.
# Для macOS и Linux
pip install x-ray
# Для Windows
python -m pip install x-ray
- Вариант 3: Запуск без установки
Если вам нужно разово проверить документ и вы не хотите засорять систему лишними пакетами, можно воспользоваться uvx.
uvx x-ray path/to/document.pdf
Теперь, когда инструмент готов к работе, перейдем к реальным сценариям использования ↓
Практика: ищем простые и скрытые дефекты ретуширования
Основная задача X-ray — подтвердить или опровергнуть факт наличия читаемого текста под графическими примитивами. Утилита принимает на вход путь к локальному файлу или URL-адрес документа.
Анализ локальных файлов
Предположим, у вас есть файл contractdraft.pdf, в котором менеджеры закрасили суммы сделки. Чтобы проверить надежность этого скрытия, выполните команду в терминале:
xray contractdraft.pdf
В случае обнаружения проблемы, инструмент вернет структурированный ответ. Рассмотрим пример реального вывода, чтобы вы понимали, как интерпретировать данные:
{
"1": [
{
"bbox": [
58.55,
72.19,
75.65,
739.39
],
"text": "The Ring travels by way of Cirith Ungol"
}
]
}
Давайте разберем структуру этого ответа:
- Ключ
"1"означает номер страницы, на которой найдена уязвимость. bbox(Bounding Box) — это массив координат[x0, y0, x1, y1], описывающий прямоугольную область, где обнаружен скрытый текст. Это позволяет вам программно подсветить проблемное место в интерфейсе вашего приложения.text— самое важное поле. Здесь содержится именно та информация, которая должна была быть скрыта, но осталась доступной (утечки данных PDF).
Работа с удаленными документами
X-ray умеет скачивать файлы напрямую, что удобно для проверки документов, хранящихся в S3-бакетах или на публичных серверах.
xray https://example.com/uploads/sensitivereport.pdf
- Важно: Убедитесь, что ссылка прямая и ведет непосредственно на PDF-файл.
Если документ содержит корректное удаление данных (когда текст физически вырезан из кода PDF, а не просто прикрыт картинкой), X-ray не вернет массив с найденным текстом. Это позволяет использовать утилиту как бинарный индикатор: «чисто» или «требует внимания».
Автоматизация безопасности: X-ray в вашем CI/CD
Использование командной строки подходит для ручных проверок, но настоящая Python security начинается там, где исключается ручной труд. Вы можете внедрить проверку на плохое замазывание PDF непосредственно в пайплайн обработки документов.
Ниже приведен пример Python-скрипта, который можно использовать в качестве шага валидации перед публикацией документа на сайте или отправкой клиенту.
Скрипт валидации (Python)
import sys
import json
# Импортируем библиотеку (название пакета может отличаться в зависимости от версии,
# проверяйте документацию, часто используется через subprocess для CLI обертки
# или прямые вызовы классов библиотеки, если они доступны в API)
import xraydef checkpdfsafety(filepath):
"""
Проверяет PDF на наличие плохо скрытых данных.
"""
try:
# В реальном проекте вызов может отличаться в зависимости от API версии
# Здесь мы эмулируем логику работы с библиотекой
# Допустим, xray.inspect() возвращает словарь с результатами
# Для демонстрации используем подход вызова через CLI wrapper или API
# Если вы используете библиотеку программно: report = xray.inspect(filepath)
if not report: print(f"✅ Документ {filepath} безопасен.")
return True
print(f"⚠️ ОБНАРУЖЕНА УТЕЧКА в файле {filepath}!")
print("Детали найденных фрагментов:")
# Парсинг отчета
for page, leaks in report.items():
print(f" Страница {page}:")
for leak in leaks:
print(f" - Скрытый текст: '{leak['text']}'")
print(f" - Координаты: {leak['bbox']}")
return False
except Exception as e:
print(f"Ошибка при проверке файла: {e}")
return Falseif name == "main":
# Пример использования в CI targetfile = "sensitivedoc.pdf" issafe = checkpdfsafety(targetfile)
if not issafe:
# Возвращаем код ошибки, чтобы прервать CI/CD пайплайн
sys.exit(1)
Интеграция в рабочий процесс
Вы можете настроить триггер в вашей системе (например, Airflow, Jenkins или GitHub Actions), который запускается при загрузке нового файла.
- Пользователь загружает PDF.
- Система сохраняет файл во временное хранилище.
- Запускается скрипт с X-ray.
- Если найдены уязвимости → файл отклоняется, администратор получает алерт.
- Если файл чист → процесс продолжается.
Такой подход гарантирует, что безопасность документов обеспечивается не внимательностью сотрудника, а строгим алгоритмом.
Сравнение: почему X-ray лучше ручной проверки и аналогов?
Может показаться, что достаточно просто внимательно смотреть на документы перед отправкой. Однако визуальный контроль неэффективен по нескольким причинам.
Во-первых, масштабируемость. Организация Free Law Project, создавшая X-ray, обрабатывает миллионы судебных документов. Проверить такой объем вручную физически невозможно. Если ваш проект генерирует сотни отчетов в месяц, программный метод — единственное решение.
Во-вторых, невидимые слои. Человеческий глаз видит только рендеринг страницы. X-ray «видит» структуру файла. Часто бывает так, что черный прямоугольник нарисован в одном слое, а текст лежит в другом. Визуально все выглядит идеально, но программно текст доступен. Ручная проверка (без попытки копирования текста) пропустит этот дефект.
В-третьих, специализация. Существуют универсальные инструменты анализа PDF (например, pdfminer или PyPDF2), но они предназначены для извлечения всего текста. X-ray заточен конкретно под задачу поиска пересечений скрывающего и текстового слоев. Это снижает количество ложных срабатываний и упрощает анализ результатов.
Однако стоит помнить о границах применимости ↓
Практические выводы
Внедрение автоматической проверки на утечки данных PDF — это необходимый шаг для любой компании, работающей с чувствительной информацией. Использование библиотеки X-ray позволяет закрыть одну из самых распространенных и глупых уязвимостей безопасности.
Подведем итог, какие шаги нужно предпринять:
- Перестаньте полагаться на визуальную проверку «замазанных» документов.
- Установите X-ray в ваше рабочее окружение через
pipилиuv. - Проведите аудит текущих документов, используя CLI-режим.
- Настройте автоматическую валидацию новых файлов на сервере.
- Обучите коллег правильному ретушированию (удалению, а не скрытию слоев).
Безопасность — это процесс, а не результат. Использование специализированных инструментов на Python делает этот процесс управляемым и предсказуемым.


